MDL meets SLT
October 14, 2025
[paper highlight: Compressibility Measures Complexity: Minimum Description Length Meets Singular Learning Theory]
two major contributions of the paper:
- theoretically links minimum description length to singular learning theory, in that they prove that for all ground-truth distributions $q$ and $n$ i.i.d samples drawn from $q,$ there exists a two-part code with asymptotic redundancy $R_n = \lambda \log n - (m-1) \log \log n + O_p(1),$ where $\lambda$ is the LLC
- experimental results showing LLC variance with model quantization (where quantization is ~roughly a stand-in for compression and LLC measures complexity, so one can study empirical correlations)
what is a two-part code? admittedly I'm still slightly bamboozled by the MDL formalism they choose, so this will be a mix of hand-wavy intuition and opaque jargon.
Let $q^{(n)} \in \Delta (\mathcal{X}^n)$ be a data-generating distribution over $n$-sequences drawn from the sample space (token vocabulary) $\mathcal{X}.$ Any distribution $p^{(n)}$ over $\mathcal{X}^n$ induces a code for any sample $\bf{x}^{(n)} \in \mathcal{X}^n,$ where a code is just an associated bitstring for the sample. The bitstring has length $- \log p^{(n)}( \bf{x}^{(n)})$ (the entropy), and the minimum description length principle is essentially that good encodings should seek to minimize the minimum average length of samples. Given i.i.d sampling, the long-run optimal encoding distribution is the ground-truth distribution $q^{(n)},$ and $\text{KL}(q||p)$ has a clean interpretation in this context: the expected excess length per-symbol given by encoding distribution $p$ vs. $q.$
a two-part code is an encoding with two parts: one specifying the encoding distribution ("model") with respect to a model class, and the other specifying the message ("sample") given the model. intuition for this setup: imagine a sender and receiver having mutual information over the fact that both will communicate via some language with some grammatical structure, but the structure insufficiently specifies a full language and vocabulary, however they both have a dictionary mapping bitstrings to complete languages that they can coordinate on first before communicating. (there are much better ways of explaining this).
anyway, you want some way of measuring the performance of your encoding in the two-part setting. there's a quantity called redundancy that measures performance with regards to the underlying data distribution, roughly given by $$ R_n = \text{len}([[p]]) + \text{KL}(q || p), $$ in the average case, where $[[p]]$ is your bitstring encoding of your model w.r.t. your model class. a natural way of optimizing this is choosing a $p$ which accurately models $q$ and eating the specification cost. However! you might have a model class $\mathcal{M}$ uniquely unsuited to encoding $q,$ in which case your optimization problem is more interesting.
restating the central theoretical result: there exists a two-part code for any realizable1 data generating distribution $q \in \mathcal{M}$ and dataset $\bf{x}^{(n)}$ sampled i.i.d from $q,$ the asymptotic redundancy is $$ R_n = \lambda \log n - (m - 1) \log \log n + O_p(1), $$ where $\lambda$ is the LLC of $q$ and $m$ is the "multiplicity."1
it is late and my brain is not quite working, but i don't see optimality guarantees for this result? the construction is of the flavor "choose codes such that
$$\text{len}([[p^*]]) = \log \frac{\text{Vol}(W)}{V_{p^*_n}(\epsilon)},$$
and then this has $R_n$ given above." (where $p^*$ are the model encodings at the center of $\epsilon$-balls covering model regions with sufficiently small KL divergence, necessary because discretization is needed to reduce to a set small enough to fully specify with codes). like, this is implicitly sane because $\text{KL}$ $\epsilon$-balls partition assigns probability proportional to the share of the $\epsilon$-ball vs. the volume of the entire space, but IDK why is this the optimal encoding or agreement algorithm? mumbles in Jeffrey's prior
a maybe helpful image:
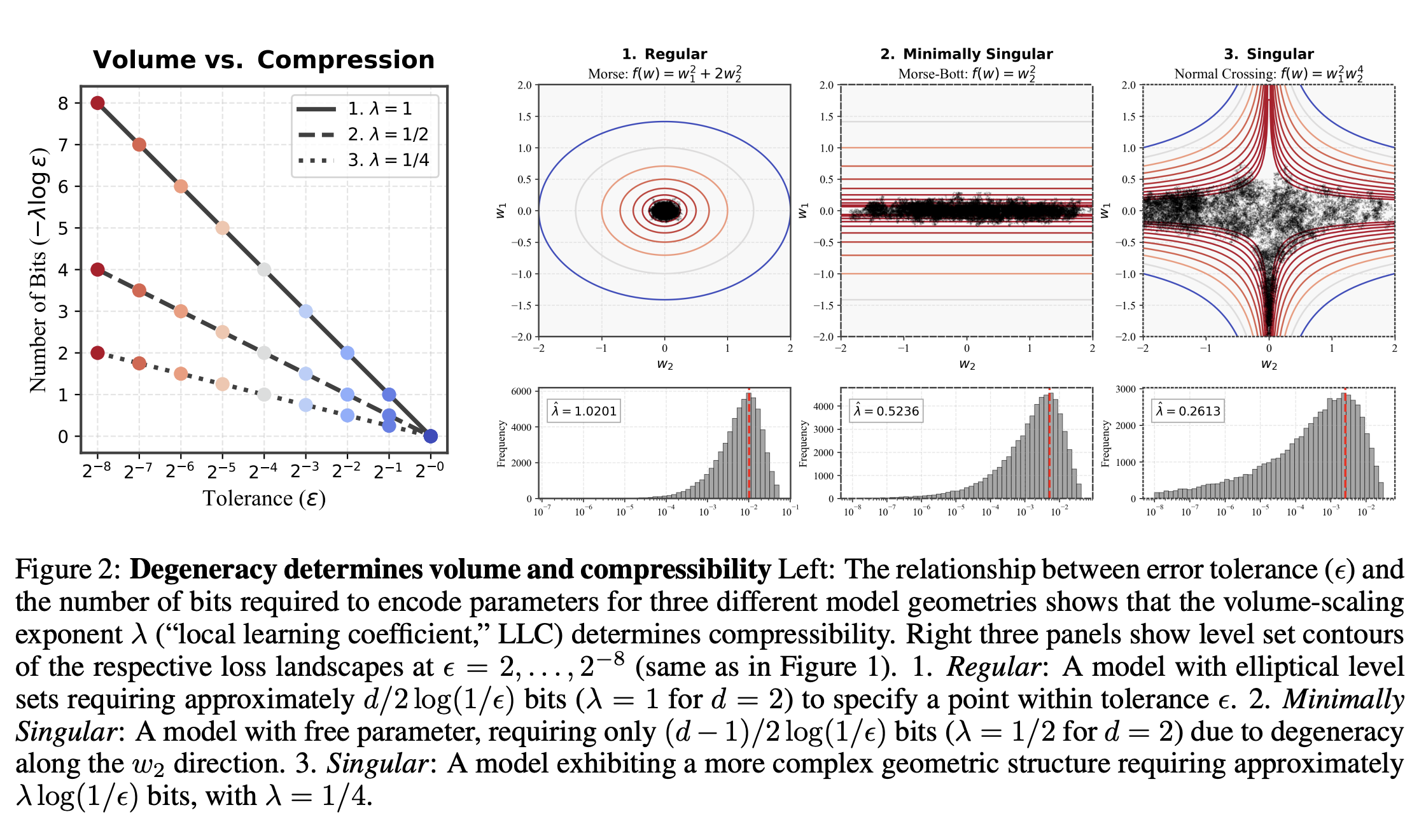
I suppose this is why the empirical results are needed. But the empirical results are like "linear relationships between LLC estimates and critical compression thresholds for models up to 7B parameters" where the critical compression thresholds $n_q$ are literally "how many times do I need to quantize the model before the difference in loss exceeds some threshold." which is cool! but a bit confusing
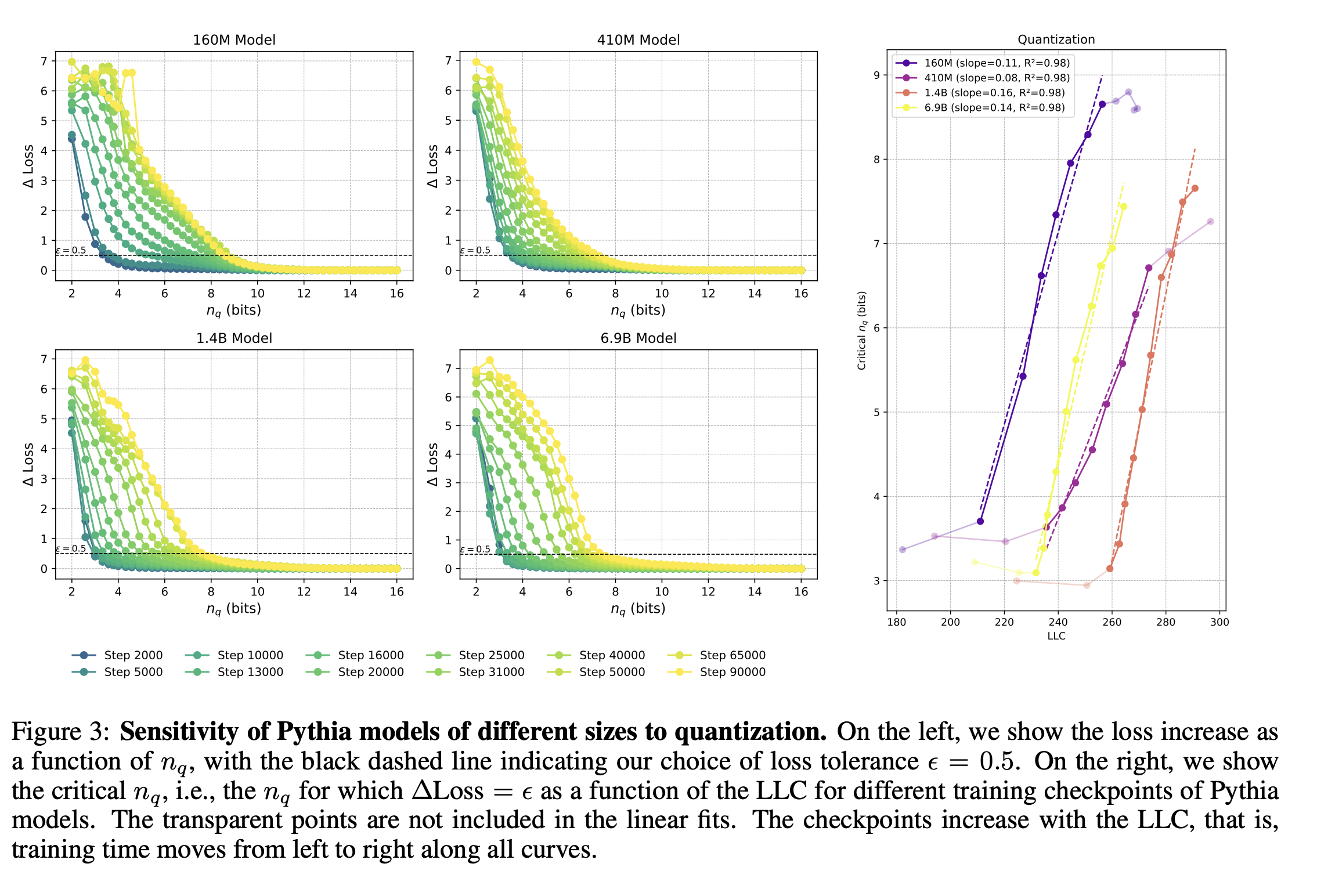
still don't quite understand the theory behind LLC estimation. MDL and SLT connections are cool though, it would be nice to get some naturality results bc the experimental results are not that convincing by themselves (many patterns replicate this, LLC estimation is an art not a science, and quantizing models arbitrarily and doing inference on them seems like it naturally leads to buggy implementations)
see technical conditions in the paper