nb: attempting a daily posting cadence. adjust quality priors accordingly
Consider the following game:
- Alice offers a contract $w: \mathcal{Y} \to \mathbb{R}^+$ to Bob.
- Bob, knowing his compact action space over lotteries $\mathcal{A} \subseteq \Delta (\mathcal{Y}) \times \mathbb{R}^+,$ chooses action $(F,c) \in \mathcal{A},$
- The output $y \sim F$ is realized (sampling from the lottery chosen)
- Alice receives $y - w(y)$ payoff; Bob receives $w(y) - c$ payoff.
Importantly, Alice receives limited information about Bob's action space (interchangeable with "technology"). What is the optimal contract Alice should give Bob, if she wants to maximize her worst case outcome? (We assume Alice and Bob are rational actors: their dynamics will be given shortly). This is an identical problem to studying the structure of the optimal $w$ in this scenario.
[Car15] proves that the optimal $w$ is linear, subject to the following assumptions: $\mathcal{Y} \subset \mathbb{R}^+,$ $\mathcal{A}$ must be compact; Alice (the "principal") knows $\mathcal{A}_0 \subseteq \mathcal{A}$ possible actions for Bob (the "agent") such that there exists $(F,c) \in \mathcal{A_0}$ such that $\mathbb{E}_F[y]-c >0$ (the principal should have some reason for hiring the agent); $w$ must be continuous.
Bob's behavior is quite simple, given that Bob has all information. The set of actions $(F,c) \in \mathcal{A}$ Bob will consider are those which maximize $\mathbb{E}_F(y) - c.$ We denote this by $\mathcal{A}^* (w | \mathcal{A}),$ and we denote by $V_A(w|A)$ the expected payoff of Bob given rational behavior. Alice's expected payoff is then
$$
V_P(w|\mathcal{A}) = \max_{(F,c) \in \mathcal{A}^*(w|\mathcal{A})} \mathbb{E}_F[y-w(y)],
$$
and Alice searches over expected payoffs as
$$
V_P(w) = \inf_{\mathcal{A} \supseteq \mathcal{A}_0} V_P(w|\mathcal{A}).
$$
We are interested in $w$ such that $V_P(w)$ is maximized.
optimality in the zero-shot game
Motivating example: $w(y) = \alpha y$ always guarantees the principal Alice positive worst-case payoff, for $\alpha \in [0,1]$. This analysis holds independently of the possible technology $\mathcal{A},$ due to the nontriviality assumption we impose on $\mathcal{A}_0.$
Proof: Rewrite $y - w(y)$ as $w(y)/\alpha - w(y) = \frac{1-\alpha}{\alpha}w(y).$ Lower bound $\mathbb{E}_F[w(y)]$ (the expected payment of Bob the agent) with $\mathbb{E}_F[w(y)] \geq \mathbb{E}_F[w(y)] - c = V_A(w|\mathcal{A})$, which is $\geq V_A(w|\mathcal{A}_0)$ (because adding more actions to the agent can't decrease the optimal outcome given $\mathcal{A}_0$). Combining the two gives
$$\mathbb{E}_F[y-w(y)] \geq \frac{1-\alpha}{\alpha}\mathbb{E}_F[w(y)] \geq \frac{1-\alpha}{\alpha}V_A(w|\mathcal{A}_0),$$
which gives $V_P(w) \geq \frac{1-\alpha}{\alpha}V_A(w|\mathcal{A}_0).$ Given the nontrivality assumption $V_A(w|\mathcal{A}_0) > 0,$ this means that this gives Alice a positive lower bound on the worst case outcome independent of the choice of technology $\mathcal{A}!$
Is there a sense in which linear contracts are "the best you can do?" Carroll shows that any contract $w(y)$ can be improved to a linear contract, even if $w(y)$ is pathological. The gist of the argument is as follows: consider the convex hull of the curve $w(y)$ that lies above the value $V_A(w|\mathcal{A}_0).$ Consider the $Q = (y',w(y'))$ point which minimizes $\mathbb{E}_F[y] - \mathbb{E}_F[w(y)].$ This is the worst case for Alice, the principal. $Q$ will typically be where $V_A(w|\mathcal{A}_0)$ intersects the left side of the convex hull. Note that the line parametrizing the intersecting boundary of this convex hull is itself a contract $w'(y)$ which dominates $w(y)!$ Repeating this process and considering some technical details gives you the optimality result.
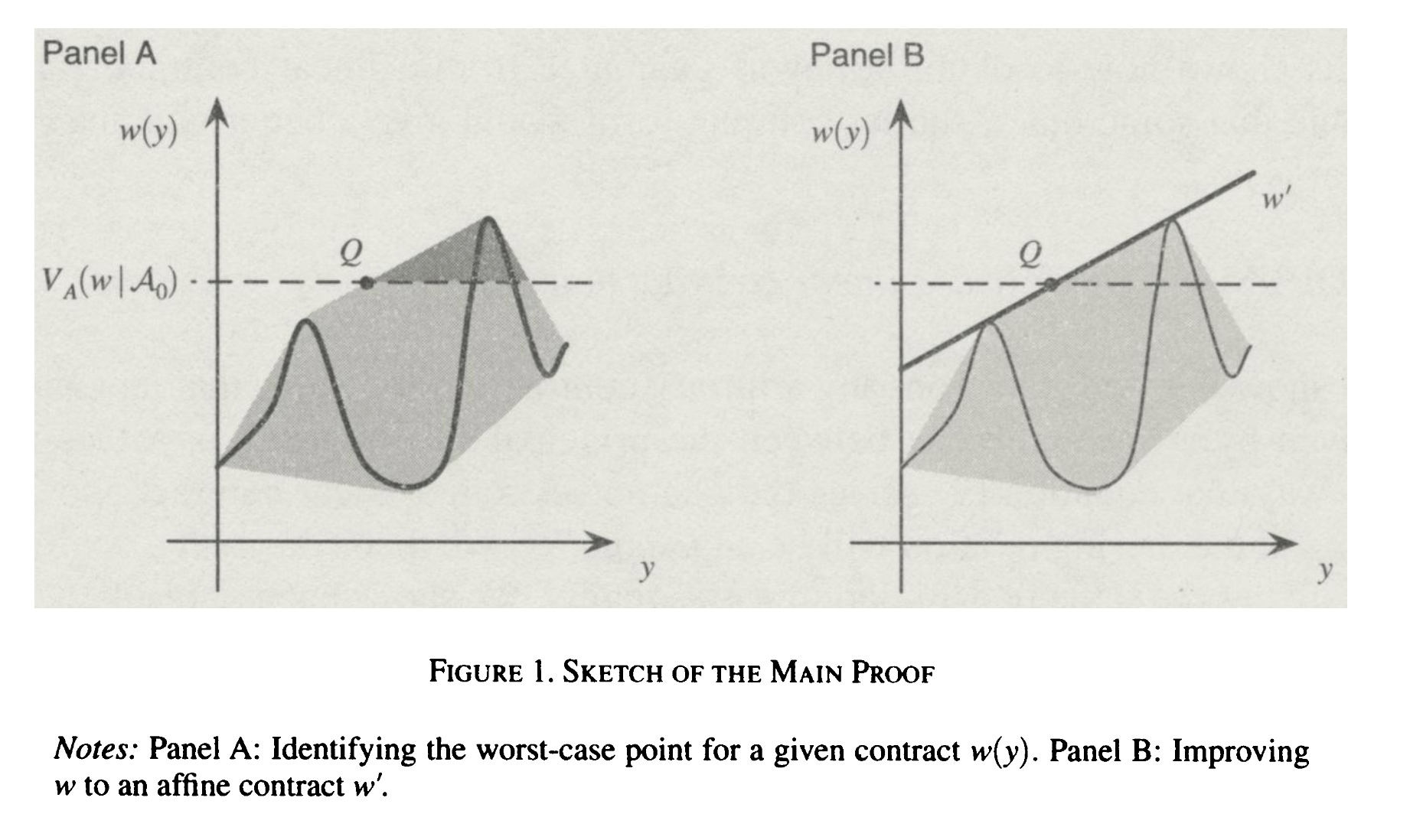
The full technical details can be found the paper, and I will not discuss them now. However, I would like to discuss the generalization of this lemma to include more observables to the principal.
Let $z = (z_1, \ldots, z_k)$ range over a compact set $\mathcal{Z} \subseteq \mathbb{R}^k.$ Define a cost function $b: \mathbb{R}^k \to \mathbb{R}^+$ such that actions depend on $b:$ an action is then $(F,c)$ such that $F \in \Delta(\mathcal{Z})$ and $c \geq b(\mathbb{E}_F(z)).$ A contract is now a function $w: \mathcal{Z} \to \mathbb{R}^+.$ Changing the definitions of $\mathcal{A}_0, V_A$ appropriately etc., it turns out the optimally robust contract is linear in the observables available to the principal. Precisely, the optimal contract is of the form
$$w(z) = \alpha_1z_1 + \cdots + \alpha_kz_k + \beta$$
for real numbers $\alpha_i, \beta.$
learnability
It seems like the linear optimality result for robust contracts is pretty general and not too sensitive to assumptions: load-bearing here is that $\mathcal{Y}$ has a minimum that we normalize to be zero, some relaxed version of the nontrivality assumption, and that the risk associated with any particular action is quantifiable in a shared manner by both the principal and the agent.
One obvious consideration: consider the possibility of unbounded risk to the principal (as suggested in UK AISI's Economics and Game Theory research agenda). It is difficult to construct contracts that then robustly protect against these scenarios, even with partial information. What are the minimum viable assumptions necessary to get guarantees in this regime?
Another consideration that I am interested in: this feels very similar to classical bandit problems in RL. Heck, the agent is engaging in the optimal bandit policy given a set of lotteries! Unifying the two literatures (perhaps [KZ25] is of interest) might tell us something interesting about certain classes of decision problems.
Also, learnable agents would (I think) perform better than static ones on a kind of mixed-objective performance metric! Perhaps one which mixes expected average and expected worst-case reward, with some weighting. Generally, intuitive restrictions & extensions on this result are things I'm excited about.